Methodology
In the following, the process of sourcing, processing, and categorizing documents for the Gender Data Library as a comprehensive and reliable repository is outlined in detail.
-
Document Sourcing
The initial step focused on sourcing relevant documents based on a carefully selected list of keywords (see Fig. 1 below) associated with gender data across various sectors. For the academic sector, Google Scholar was used to collect documents, retrieving the first 20 articles for each keyword search. This approach provided a broad spectrum of scholarly research related to gender issues in Burkina Faso. For international organizations, documents were sourced from digital libraries of key bodies such as the UN, WFP, WHO, World Bank, FAO, ILO and IOM. These organizations were selected due to their significant contributions to gender-related research and policy documents. Some additional sources from international organizations will be incorporated into the repository at a later stage, like UN Womens rather small amount of online resources. For political institutions, all available documents from various ministries that were accessible online were collected. In addition, the FAO’s FAOLEX database of legal texts was incorporated. This comprehensive sourcing strategy ensured the inclusion of a wide range of documents from multiple sources, covering key perspectives on gender data from global, regional, and local levels. -
Document Processing
Once the documents were collected, a systematic processing phase was initiated to prepare the data for analysis and classification. First, the text from each document was extracted. If the document was in a scanned format, Optical Character Recognition (OCR) was applied to convert it into machine-readable text. After text extraction, the language of each document was detected using a Google’s open-source language detection library to facilitate proper classification and subsequent analysis. To ensure consistent tracking and management, IDs were generated through hashing of the parsed text for each document, which were then used throughout the subsequent stages to maintain consistency and prevent duplication. -
Removal of Duplicates and Unrelated Documents
To avoid redundancy and maintain the quality of the library, duplicate documents and documents not related to Burkina Faso were systematically removed. For the duplicate removal, IDs were compared to identify identical documents across the dataset. When duplicates were found, only one instance of each document was retained. For the removal of documents not related to Burkina Faso, a document was kept when it either contained ‘Burkina Faso’ in the title or at least 8 times in the document’s text. This ensured the country focus throughout the document corpus. -
Description Retrieval
During the document collection process, it was observed that only for about 30% of the documents a description or abstract was collected as metadata in the document sourcing stage. To address this gap, Meta AI’s newest Llama 3.1 8B model was employed to automatically generate missing descriptions, as well as to extract relevant metadata such as dates and titles. Due to limitations of computational resources, the model was applied to the first 2,000 characters of each document (approximately the first 1-2 pages of text) to generate concise and contextually accurate summaries. -
Document Scoring
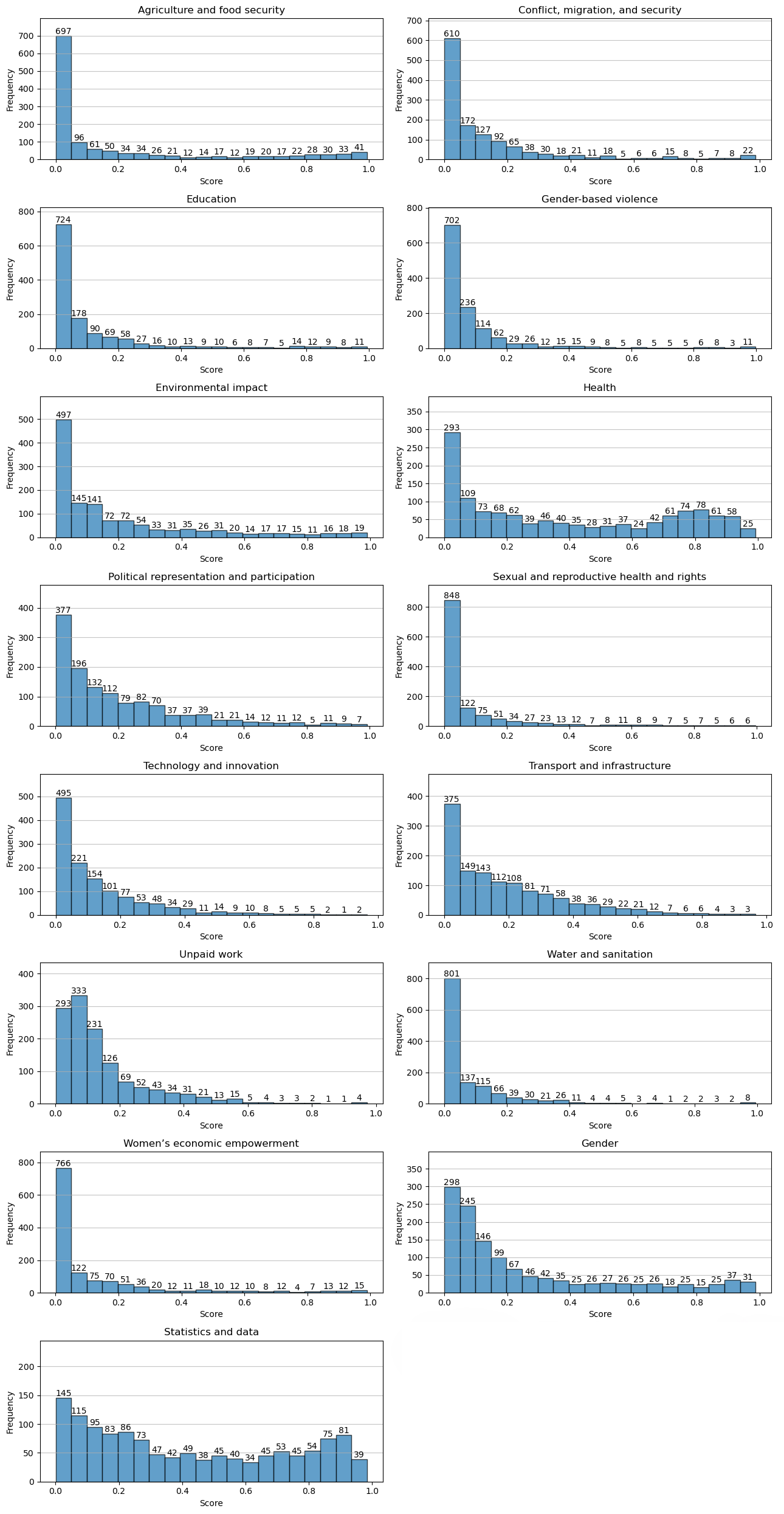
To categorize and prioritize documents effectively, each document description was evaluated and scored on a scale from 0-1 using Meta AI’s zero-shot classifier, BART-Large-MNLI. This model was used to classify the documents into 13 predefined gender categories, such as education, health, economic empowerment, and social inclusion. Additionally, two extra categories — “Gender” and “Statistics and Data” — were included to reduce the library only to the documents focused on gender data. The scores indicate the relevance of each document to these categories, allowing users to filter and prioritize documents based on their specific interests and needs. -
Cutoff Definitions
To maintain a focused and relevant library, cutoff thresholds were established for inclusion. For the categories “Gender” and “Statistics and data” a cutoff score of 0.1 was defined (see Fig. 2 below). Documents scoring below this threshold were filtered out to exclude those not sufficiently related to gender data topics. This step ensured that the library remained targeted and relevant, providing users with high-quality documents that align with their search criteria and the library’s objectives.
Limitations
- Url-based document library: Documents are accessed through urls to the respective source website. Due to changes on the source website, the original url can change and therefore the displayed url won’t lead to the correct website anymore. A websearch using the document title can be used to identify the document in case of interest.
- Search Engine Limitations: During the document sourcing for academic articles, the approach relied on Google Scholar’s search algorithm, which is not publicly available and therefore shares the same limitations. However, it can be assumed that a sophisticated algorithm is used to make the search as effective as possible.
- Duplicate Removal: For the removal of duplicates, the approach only removes documents if they contain exactly the same content through the comparison of their IDs (hashed PDF content). Documents that are just slightly different (e.g., documents with an additional title page) would not be excluded.
- Partial Text Analysis: When trying to retrieve document descriptions, only the first 2000 characters are taken into account due to computational limitations. Usually, this captures a wide enough context to generate a fitting description, but it can lead to inaccurate descriptions in some cases.
- Model Limitations for Relevance Scoring: Due to the issue of missing labeled data for the predefined categories, the zero-shot classifier BART-Large-MNLI was employed. As a zero-shot classifier, it has not been specifically trained for gender data-focused texts. This may reduce accuracy compared to models fine-tuned on relevant datasets.