Méthodologie
Voici un aperçu détaillé du processus de recherche, de traitement et de catégorisation des documents pour la Bibliothèque des Données sur le Genre, en tant que dépôt complet et fiable.
-
Recherche de documents
La première étape consistait à rechercher des documents pertinents en se basant sur une liste soigneusement sélectionnée de mots-clés (voir Fig. 1 ci-dessous) associés aux données de genre dans divers secteurs. Pour le secteur académique, Google Scholar a été utilisé pour collecter des documents, en récupérant les 20 premiers articles pour chaque recherche de mots-clés. Cette approche a permis d’obtenir un large éventail de recherches académiques liées aux questions de genre au Burkina Faso. Pour les organisations internationales, des documents ont été extraits des bibliothèques numériques de grands organismes tels que l’ONU, le PAM, l’OMS, la Banque mondiale, la FAO, l’OIT et l’OIM. Ces organisations ont été choisies en raison de leur contribution significative aux recherches et documents politiques liés au genre. D’autres sources d’organisations internationales seront intégrées à une étape ultérieure, comme le petit nombre de ressources en ligne d’ONU Femmes. Pour les institutions politiques, tous les documents disponibles des différents ministères accessibles en ligne ont été collectés. De plus, la base de données FAOLEX de la FAO sur les textes juridiques a été incluse. Cette stratégie de recherche complète a permis d’inclure une large gamme de documents provenant de multiples sources, couvrant des perspectives clés sur les données de genre aux niveaux mondial, régional et local. -
Traitement des documents
Une fois les documents collectés, une phase de traitement systématique a été lancée pour préparer les données à l’analyse et à la classification. Tout d’abord, le texte de chaque document a été extrait. Si le document était au format numérisé, la reconnaissance optique des caractères (OCR) a été appliquée pour le convertir en texte lisible par machine. Après l’extraction du texte, la langue de chaque document a été détectée à l’aide de la bibliothèque open-source de détection des langues de Google pour faciliter la classification et l’analyse ultérieures. Pour assurer une gestion et un suivi cohérents, des IDs ont été générés par hachage du texte extrait pour chaque document, lesquels ont ensuite été utilisés tout au long des étapes suivantes afin de maintenir la cohérence et d’éviter les doublons. -
Suppression des doublons et des documents non liés au Burkina Faso
Afin d’éviter les redondances et de maintenir la qualité de la bibliothèque, les doublons ainsi que les documents non liés au Burkina Faso ont été systématiquement supprimés. Pour la suppression des doublons, les IDs ont été comparés afin d’identifier les documents identiques dans l’ensemble de données. Lorsqu’un doublon était identifié, une seule instance du document était conservée. Pour la suppression des documents non liés au Burkina Faso, un document était conservé s’il contenait soit « Burkina Faso » dans le titre, soit au moins 8 occurrences de cette mention dans le texte du document. Cela garantissait un focus sur le pays dans l’ensemble du corpus documentaire. -
Récupération des descriptions
Au cours du processus de collecte des documents, il a été observé que seules environ 30 % des descriptions ou résumés étaient collectés comme métadonnées lors de l’étape de recherche de documents. Pour combler cette lacune, le modèle Llama 3.1 8B de Meta AI a été utilisé pour générer automatiquement les descriptions manquantes, ainsi que pour extraire des métadonnées pertinentes telles que les dates et les titres. En raison des limitations des ressources informatiques, le modèle a été appliqué aux 2 000 premiers caractères de chaque document (environ les 1 à 2 premières pages de texte) afin de générer des résumés concis et contextuellement précis. -
Évaluation des documents
Pour catégoriser et prioriser efficacement les documents, chaque description de document a été évaluée et notée sur une échelle de 0 à 1 en utilisant le classificateur zero-shot de Meta AI, BART-Large-MNLI. Ce modèle a été utilisé pour classifier les documents dans 13 catégories de genre prédéfinies, telles que l’éducation, la santé, l’autonomisation économique et l’inclusion sociale. De plus, deux catégories supplémentaires — “Genre” et “Statistiques et données” — ont été incluses pour ne conserver que les documents portant sur les données de genre. Les scores indiquent la pertinence de chaque document par rapport à ces catégories, permettant aux utilisateurs de filtrer et de prioriser les documents en fonction de leurs intérêts et besoins spécifiques. -
Définition des seuils
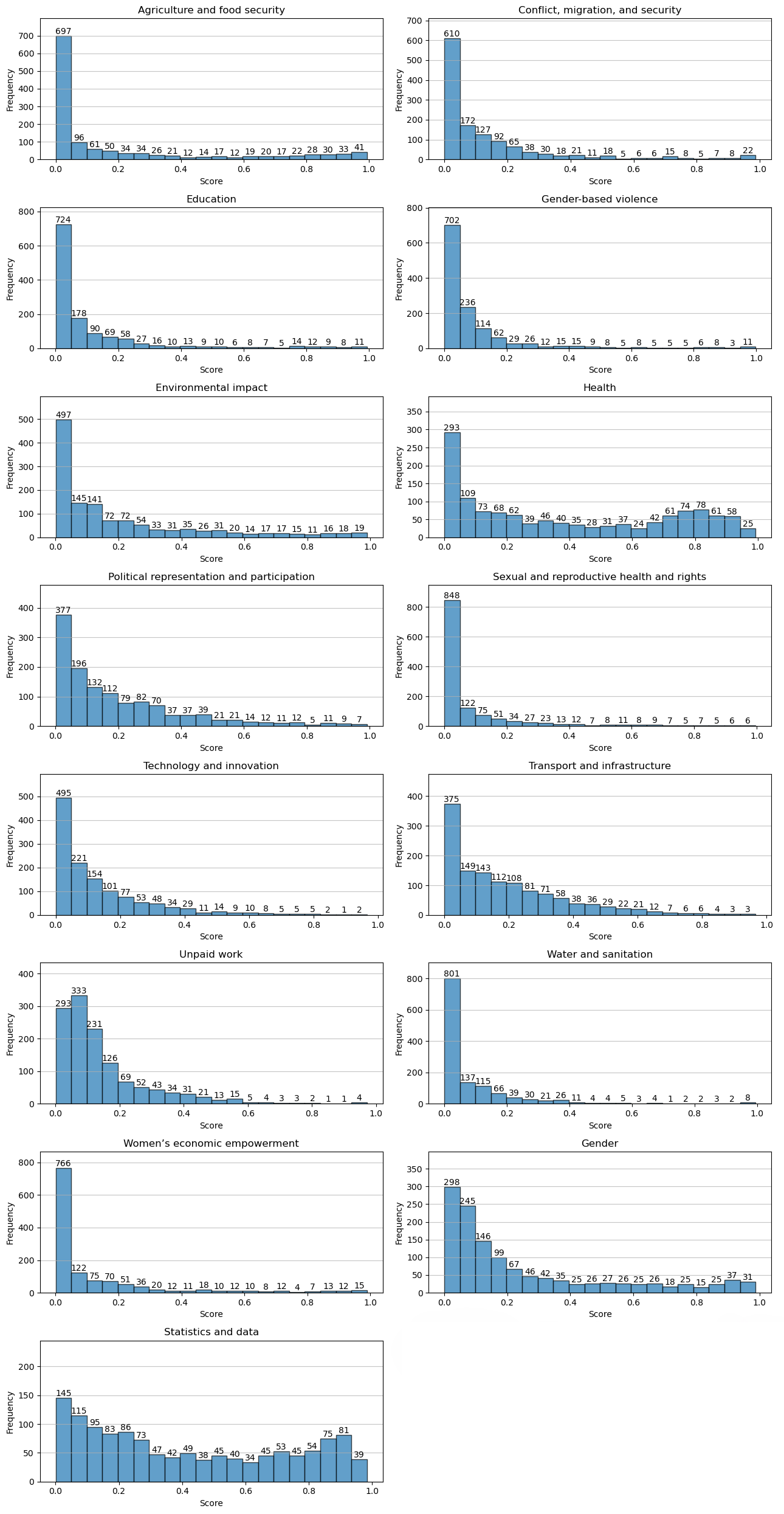
Pour maintenir une bibliothèque ciblée et pertinente, des seuils de pertinence ont été définis pour l’inclusion des documents. Pour les catégories “Genre” et “Statistiques et données”, un seuil de 0,1 a été défini (voir Fig. 2 ci-dessous). Les documents dont les scores étaient inférieurs à ce seuil ont été filtrés afin d’exclure ceux qui n’étaient pas suffisamment liés aux sujets de données de genre. Cette étape a permis de garantir que la bibliothèque reste ciblée et pertinente, fournissant aux utilisateurs des documents de haute qualité alignés sur leurs critères de recherche et les objectifs de la bibliothèque.
Limitations
- Bibliothèque de documents basée sur des URL : Les documents sont accessibles via des URL menant au site source respectif. En raison de modifications apportées au site source, l’URL d’origine peut changer et ne plus conduire au bon site. Une recherche web à l’aide du titre du document peut être effectuée pour retrouver le document en cas d’intérêt.
- Limitations du moteur de recherche : Lors de la recherche de documents académiques, l’approche s’est appuyée sur l’algorithme de recherche de Google Scholar, qui n’est pas accessible au public et partage donc les mêmes limitations. Cependant, on peut supposer qu’un algorithme sophistiqué est utilisé pour rendre la recherche aussi efficace que possible.
- Suppression des doublons : Pour la suppression des doublons, l’approche élimine uniquement les documents qui contiennent exactement le même contenu en comparant leurs identifiants (contenu PDF haché). Les documents légèrement différents (par exemple, un document avec une page de titre supplémentaire) ne seraient pas exclus.
- Analyse partielle du texte : Lors de la récupération des descriptions de documents, seuls les 2000 premiers caractères sont pris en compte en raison de limitations informatiques. En général, cela capture un contexte suffisant pour générer une description adaptée, mais cela peut parfois conduire à des descriptions inexactes.
- Limitations du modèle pour l’évaluation de la pertinence : En raison du manque de données étiquetées pour les catégories prédéfinies, le classificateur à zéro-shot BART-Large-MNLI a été utilisé. En tant que classificateur à zéro-shot, il n’a pas été spécifiquement entraîné sur des textes axés sur les données de genre. Cela peut réduire la précision par rapport à des modèles ajustés sur des ensembles de données pertinents.